8 minutes
Specification of a OBD-II firewall

After we have dealt with the possible threats of OBD-II dongles within the CAN protocol in the last post (Threat Modeling for OBD-II), it is now time to think of a suitable way to prevent them. We will present the entire architecture of software and hardware in. Then we will specify how the OBD-II firewall can be managed in detail. We will then deal with the administration of the individual rules. Finally, we will explain how the enforcement of the individual rules can be done.
Architecture
In this section we will lay the foundation for the individual system components, which we will then later implement. In general, the architecture is divided into two sections. One is all the software components and the other is the associated hardware that utilises the software.
Software Components
A complete detailed specification of all software components would be inappropriate and out of scope. Nevertheless, we would like to briefly explain the basic ideas of the respective components in theory and show why we choose exactly this approach. Therefore, we will briefly outline the most important parts in the next subsections.
Producer/Consumer Scheme
The producer-consumer problem (also known as the bounded buffer problem) is a classic example of a multiprocess synchronisation issue, the first version of which dates back to Edsger W. Dijkstra in 1965. Nevertheless, there are now promising approaches in software development to efficiently eliminate this problem [1]. A filtering approach is best realised with a buffer in which incoming messages are accumulated. Afterwards, they can be processed one after the other, depending on the queue. To be as unrestricted as possible in terms of processing, this model is also perfect. Depending on the respective computing power, several producers or consumers can be started. In this way, load peaks can be easily absorbed. The modular approach can also be applied by means of differently implemented producers.
Modular Approach for Protocol Bindings
Since the producer/consumer scheme allows us to easily create several differently implemented producers, a uniform interface must be defined. This interface ensures that the responsible consumer can correctly process and forward the incoming messages. By means of this approach it is possible to support incoming messages of all protocols.
CAN-Bus Binding
In order to support the CAN protocol for our implementation, a connector is needed to receive messages as well as to be able to send filtered or processed messages again. For this purpose, already used libraries as well as the common syntax for encoding and decoding are going to be used. Furthermore, it is desirable if the binding understands the so-called DBC format. DBC stands for CAN Database and is a proprietary format that describes the data structure over a CAN bus. A CAN DBC file is a text file that provides all the necessary information for decoding CAN bus raw data into physical values.
Processing Pipeline
A concurrent and multi-level data input and data processing pipeline is to be realised for the processing pipeline. It must also be possible to efficiently consume different sources, the so-called producers. It would also be desirable if there was the possibility to configure the processing pipeline with regard to the resources to be used. More precisely, the number of processes for producer and consumer as well as the concurrency and the batch size to be used. In the figure below you can see an schematic overview of the pipeline. The blue circles in the figure symbolise the producers. As already mentioned, it will be possible to develop a producer for each protocol. So in the future there may be a producer for CAN, one for ISO9141 and so on. There is a uniform interface to adhere to. The producers then send their messages to the concurrent and multi-stage data ingestion service. There, the incoming messages should be analysed and then asynchronously serialised and inspected. Here, serialisation refers to the application of the active rules and not to the quantity of messages.
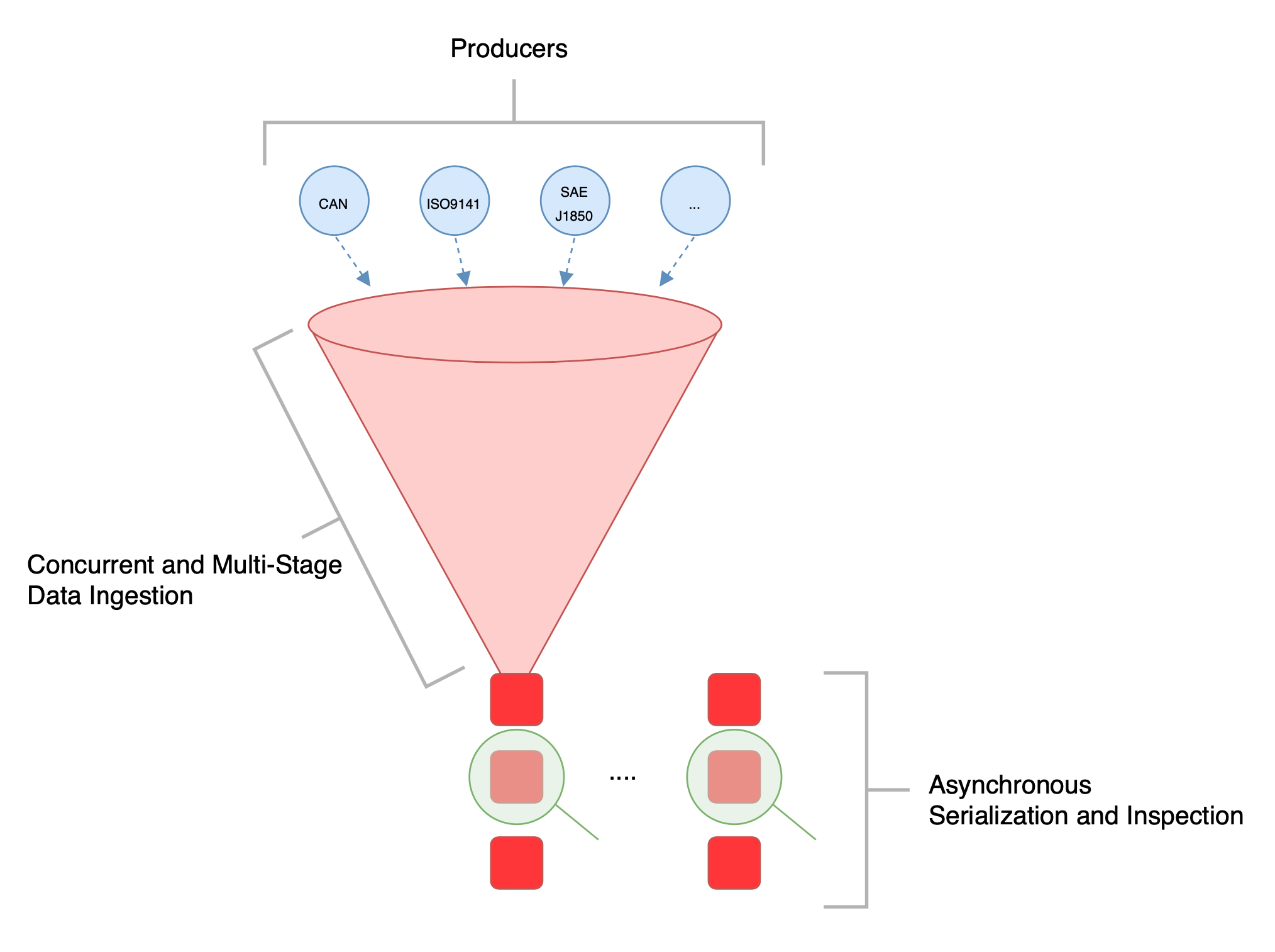
Serialization
After the incoming messages have been serialised and bundled into batches, the messages are to be checked for the active rules as efficiently as possible. Since the behaviours of a rule can be sorted according to their strictness in the restriction, the strictest behaviours should currently apply. This allows the individual behaviours to carry out the checks in parallel.
Data Storage
It should be possible to record the data as well. In the best case, data should be stored in a database in a uniform, reusable format. This ensures that the logged CAN messages can be easily searched or filtered for various purposes. Since the amount of CAN messages can be immense, there should be an option to deactivate or activate the permanent logging.
Hardware Components
The following list shows all the hardware components required for our approach. We will discuss why and how the individual components are used in more detail in one of the following blog posts.
- Raspberry Pi 4 Model B 8GB RAM
- SunFounder StemEducation 10.1" Touch Screen
- Seed 2-Channel CAN-BUS(FD) Shield for Raspberry Pi
- Custom made cable for taping CAN wires from OBD-II
- Custom made cable for plugging OBD-II dongles into firewall
Interfacing the OBD-II firewall
One of the most important parts in our firewall is the connection to the OBD-II interface. The connection from our firewall to the outside should not have any difference for the end-user compared to the conventional OBD-II connector. The final prototype of this thesis shall be a setup with a female connector port and a male adapter cable. The female port will be used for connecting devices that are filtered by our firewall. The male connector will be used to connect the firewall to the existing OBD-II interface of the respective vehicle. In order to implement our filtering approach safely, there must be a clear and physical separation between the CAN interface for the incoming messages (i.e. the interface where you then connect the dongle) and the CAN interface which is responsible for sending or passing on the data to the OBD-II interface.
Policy Management
Policies are managed using configurations specified in JSON format. We do not currently use any particular rule framework or rule engine. The format is a simple one that is adapted to the current use case, but can be extended in a modular way. The current overall structure can be seen in tables 1 and 2.
In any case, a kind of version check must be carried out at implementation stage for the respective rules to be applied. On the other hand, extensibility is almost impossible or backwards compatibility cannot be guaranteed. Table 1 shows the overall wrapper structure for a rule definition. This contains general information such as a description, the protocol type to be filtered and the version of the policy language currently in use. Table 2 describes the structure of a so-called behaviour. A rule can theoretically have as many behaviours capsules as desired. An example of a possible rule can be found in snippet 1. Here, each currently available behaviour type (namely reject, limit and repalce) is applied once for demonstration purposes.
| Property | Type | Description |
|---|---|---|
| name | <String> | Is just a simple naming of the individual rules for better distinction. The name does not have to be unique. |
| description | <String> | Briefly describes the created rule in a few words. |
| version | <String> | The version number specifies the version of the properties to be used. |
| protocol | <Protocol-Type> | Declares the protocol type to be used for the respective rule. Currently there is only <CAN> as a declarable type. However, due to the modular approach, more types may be added in the future. |
| behaviours | [<Behaviour>] | The behaviour field defines a list of all actions to be performed later during the execution of each rule. More information about the types available within a behaviour can be found in table 2. |
| Property | Type | Description |
|---|---|---|
| type | <String> | Currently, three different behaviour types are supported: - reject - limit - replace |
| identifier | <String> | Defines the identifier of the CAN message present on the bus. |
| value | <String> | Determines the data payload to be used for the respective set type . |
| delay | <Integer> | If the delay property is set, all messages that fall below the specified behaviour will be delayed. The value is given as an integer value and defines the delay time in milliseconds. |
| pub*once | *<Boolean>_ | Allows messages in the scope of the behaviour to be allowed only once per system start. Once the message has been read once, it is whitelisted and then not forwarded. By default, the value is set to false. |
| id_range | <String> | By means of the identifier range, the behaviour value range to be enforced can be extended. |
| val_range | _<String>_ | Allows messages in the scope of the behaviour to be allowed only once per system start. Once the message has been read once, it is whitelisted and then not forwarded. By default, the value is set to false. |
| |
Rule enforcement
The enforcement of the rules as well as the individual behaviours should be based on an assessment of importance. This means that more important behaviours and rules outweigh lower ones. Furthermore, it should be possible to easily deactivate and activate individual rules. Also, it is interesting to get some specific metrics related to rule/behaviour enforcement. Therefore, the number of filtered, modified and blocked messages should be tracked.
References
[1] Leslie Lamport. “A New Solution of Dijkstra’s Concurrent Programming Prob- lem”. In: Concurrency: The Works of Leslie Lamport. New York, NY, USA: Associa- tion for Computing Machinery, 2019, pp. 171–178. ISBN: 9781450372701.